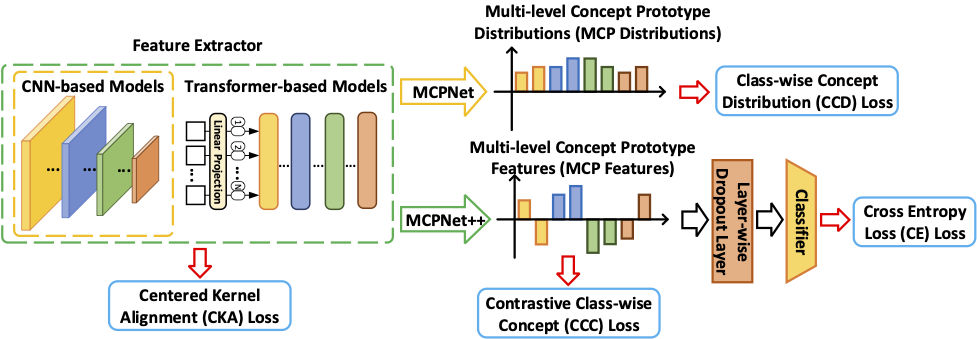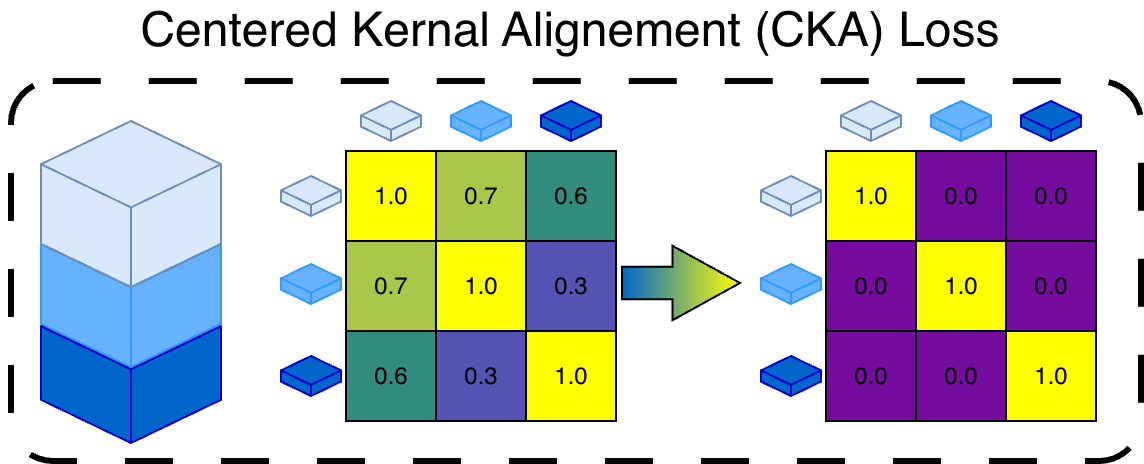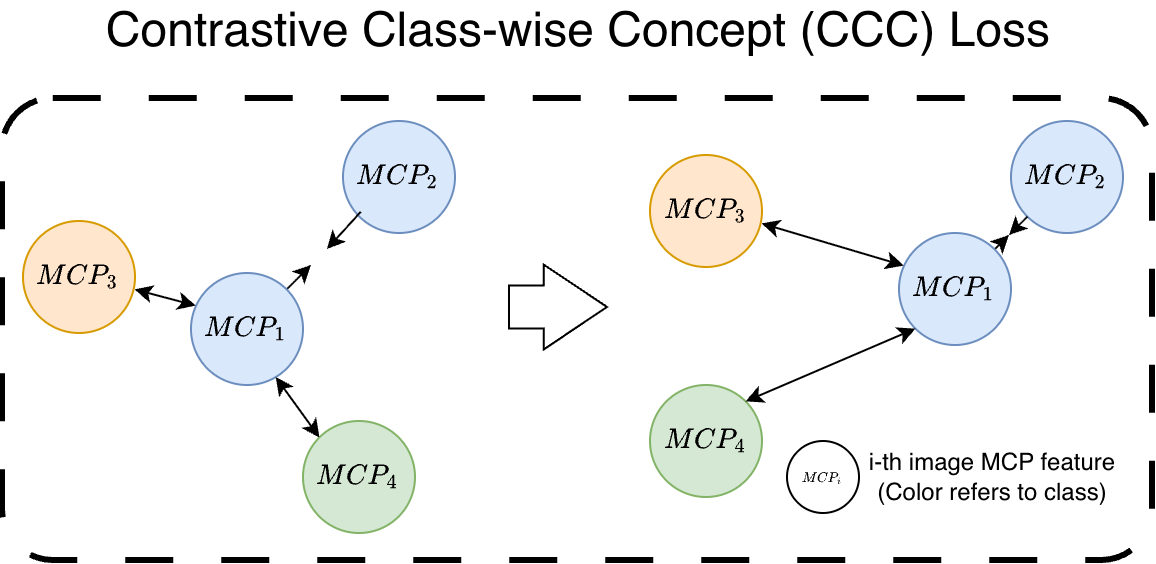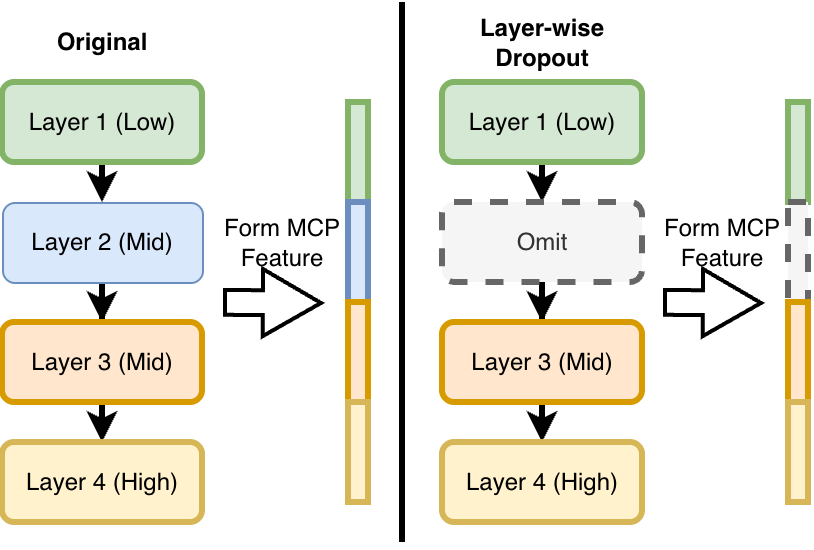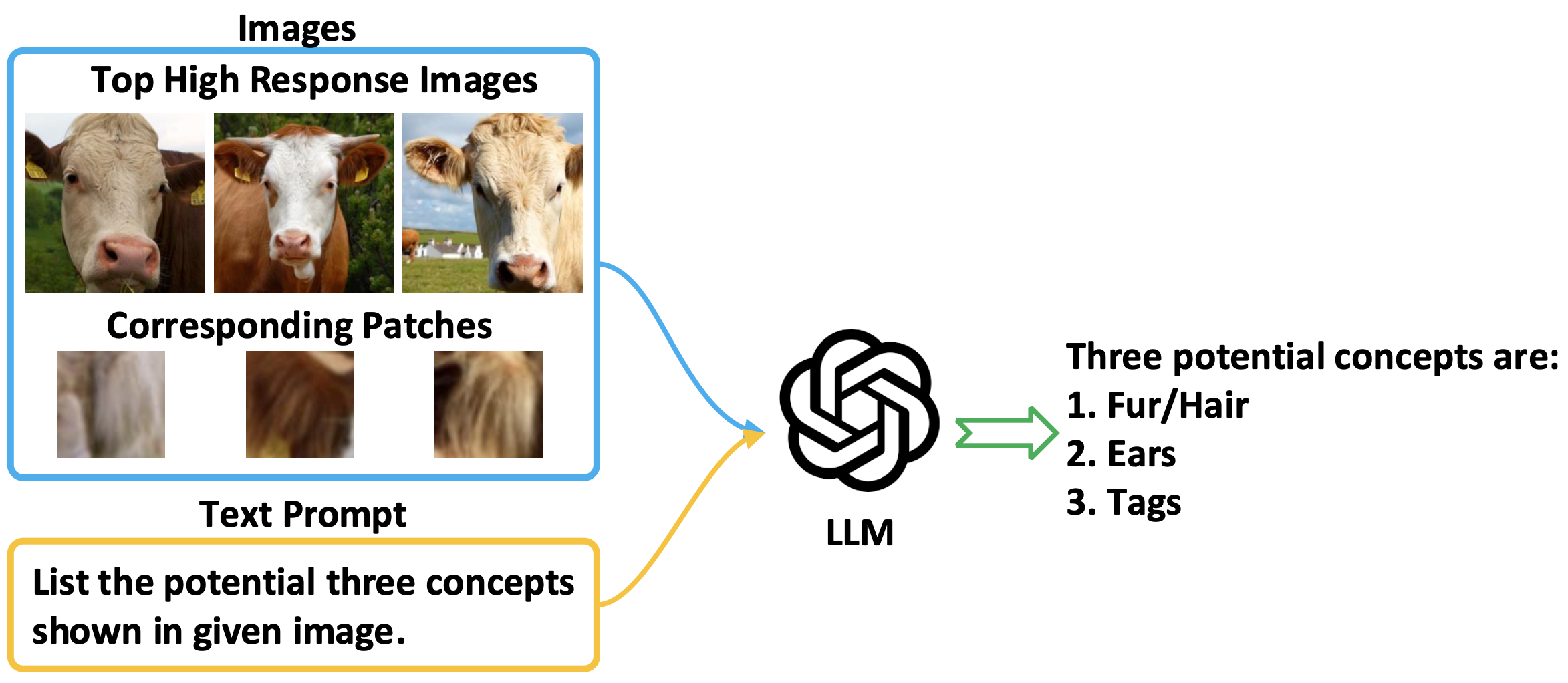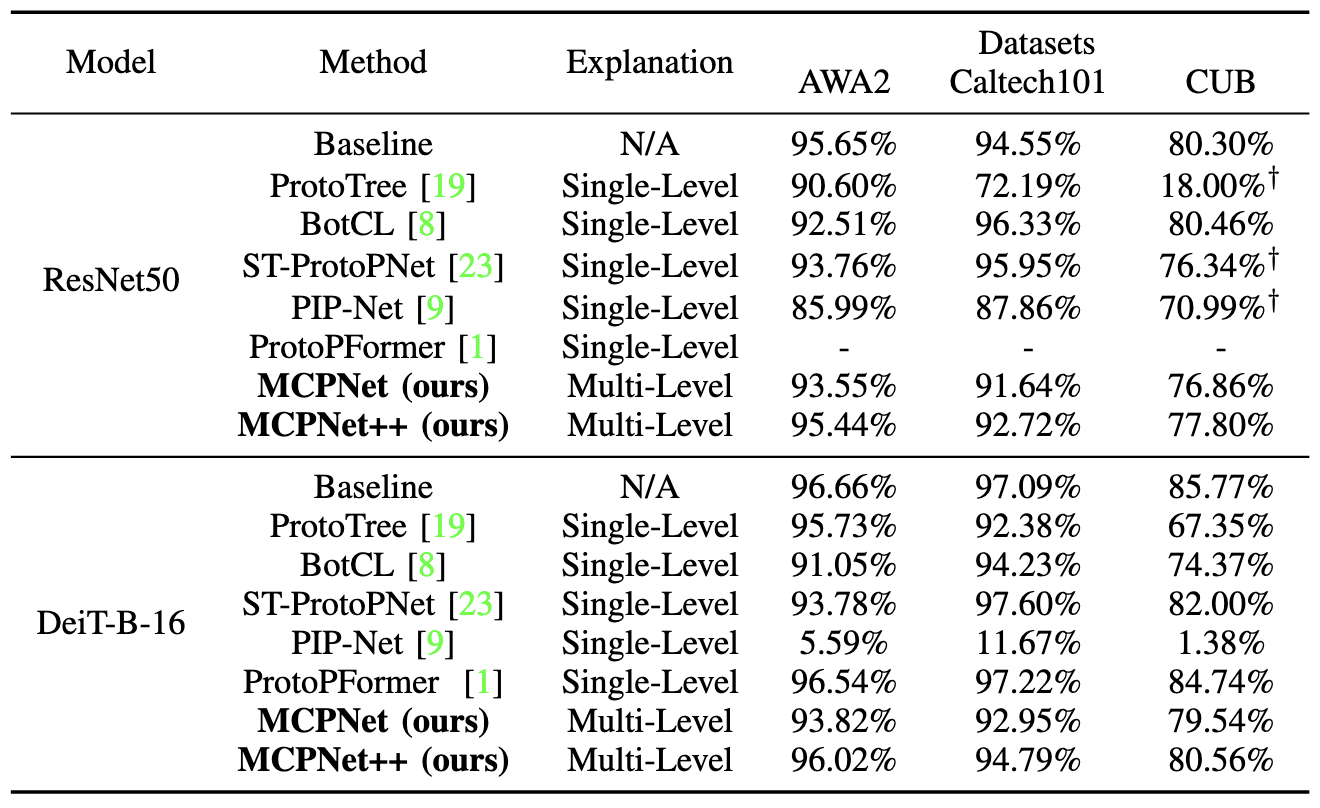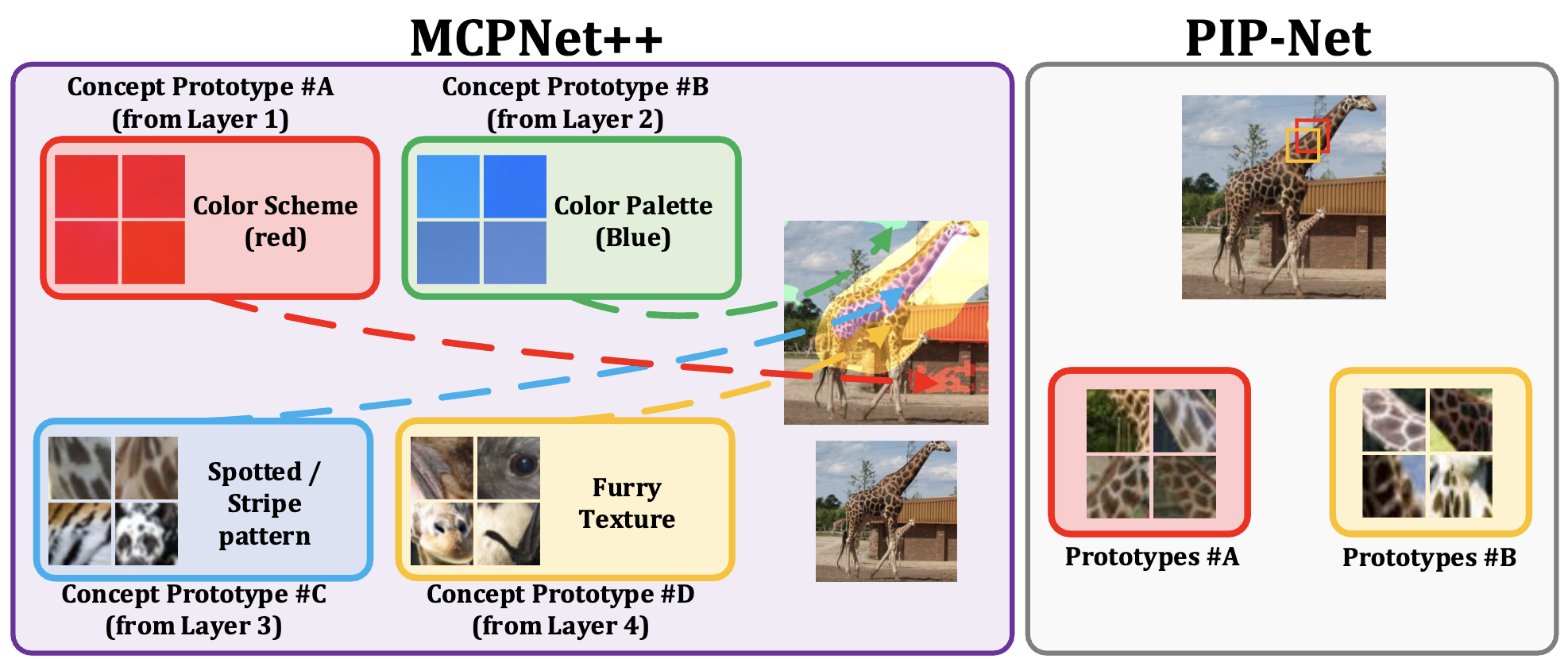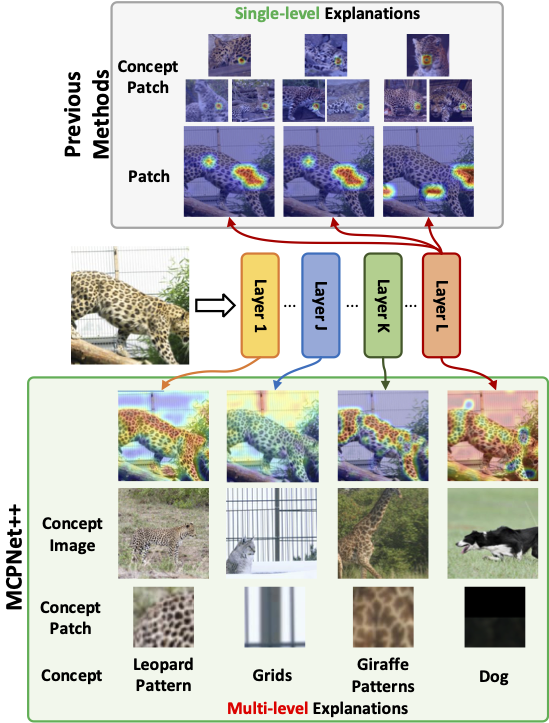
| MCPNet | MCPNet++ | ProtoPNet | ProtoPFormer | BotCL | Concept Bottleneck Model | VCC | CRAFT*** | TCAV | |
|---|---|---|---|---|---|---|---|---|---|
| Explanation Type | Inherently | Inherently | Inherently | Inherently | Inherently | Inherently | Post-hoc | Post-hoc | Post-hoc |
| Explanation Scale | Multi-level | Multi-level | Single-level | Single-level | Single-level | Single-level | Multi-level | Single-level | Single-level |
| w/o Concept Labels | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✗** |
| Available for CNN and Transformers |
✓* | ✓ | ✓* | ✗ | ✓* | ✓* | ✓ | ✓* | ✓* |
* Applicable to CNN backbones only (not transformers) in original work. ** TCAV requires user-defined concept examples. *** CRAFT is a post-hoc method applied after training.